Alexander Mezga
Backend Engineer | Data Infrastructure & Architecture
A curated collection of my technical notes
Read My NotesAbout Me
I’m a backend engineer specializing in scalable systems and data infrastructure. I focus on building reliable foundations for analytics and data-driven products — from pipelines to backend features that rely on them.
I design and maintain data pipelines and backend services that support both internal analytics and customer-facing functionality. My responsibilities include system architecture, high-volume data processing, performance tuning, and integration with third-party platforms — all with a strong focus on reliability, maintainability, and data quality.
Working at an analytics platform for businesses — a product that helps turn customer reviews and support interactions into actionable insights. I’m responsible for the data pipelines and infrastructure that power the analytics — from ingesting and structuring raw data to ensuring it’s queryable, reliable, and ready for downstream use.
I’m passionate about software architecture and engineering culture — building systems that are stable, easy to evolve, and resistant to long-term technical debt.
Experience
Tbilisi, Georgia · Remote
I design and maintain backend services and scalable data pipelines for processing and storage. I'm responsible for the architecture, reliability, and quality of systems that power analytics and data-driven product features.
- Designing and implementing reliable data pipelines
- Integrating and maintaining a corporate Data Lake (S3 + Apache Iceberg)
- Storing and processing large volumes of data (PostgreSQL, ClickHouse)
- Developing backend services and APIs in Python (FastAPI, asyncio)
- Asynchronous and parallel data processing with cross-system state synchronization
- Optimizing processing speed, controlling latency, and ensuring overall performance
- Building systems and codebases that are easy to extend and maintain
- Ensuring data quality: deduplication, validation, and end-to-end monitoring
- Communicating with external partners and integrating their solutions
Haifa, Israel
While working on various projects, I had to solve many engineering and architectural problems.
- Backend development in Python
- Backend development for NLP projects
- Development of service and microservice architectures
- Development and scaling of data pipelines
- Design and development of API services
- Scaling of systems, optimization of computing resources
- Database design, optimization of data storage and retrieval processes
- Deployment of solutions on servers and in the cloud (AWS, GCP)
- Development and optimization of algorithms
- Creation and deployment of deep learning models for computer vision and NLP
- Construction of full-text search systems, data visualization, data clustering
- Implementation of machine learning models in data processing pipelines
Rostov-on-Don, Russia
Taking the course and solving problems for the CS231n. Solved classical computer vision tasks on QT/C. Deployed algorithm for Carvana Image Masking competition.
Skills
Education
Advanced studies in computer science with focus on data systems and algorithms.
Foundation in mathematical principles and computer science fundamentals.
Projects
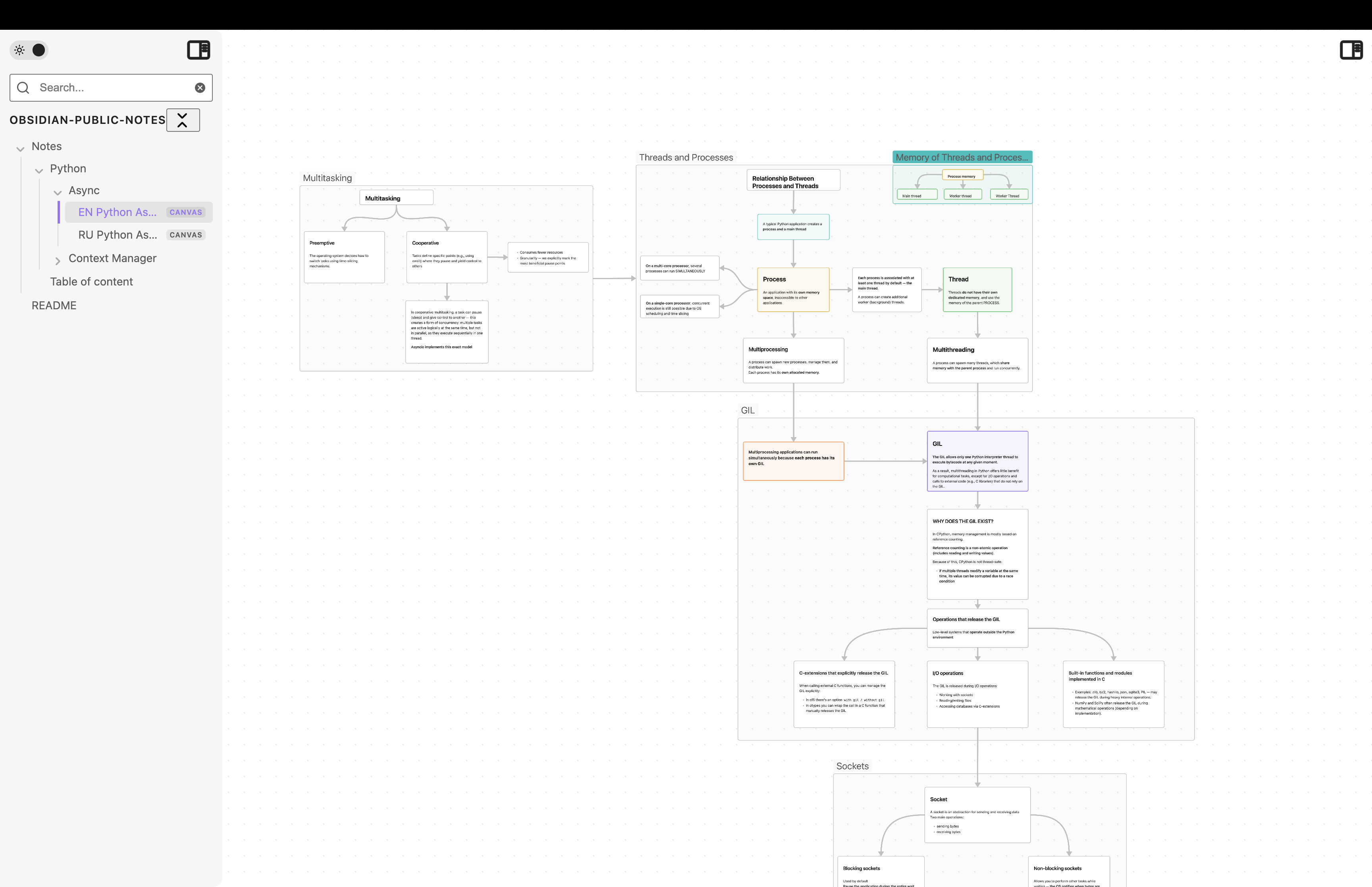
A collection of my technical notes written in Obsidian, covering topics like backend architecture, data engineering, and async processing. The notes are published as a static website and the original Obsidian files are available on GitHub.
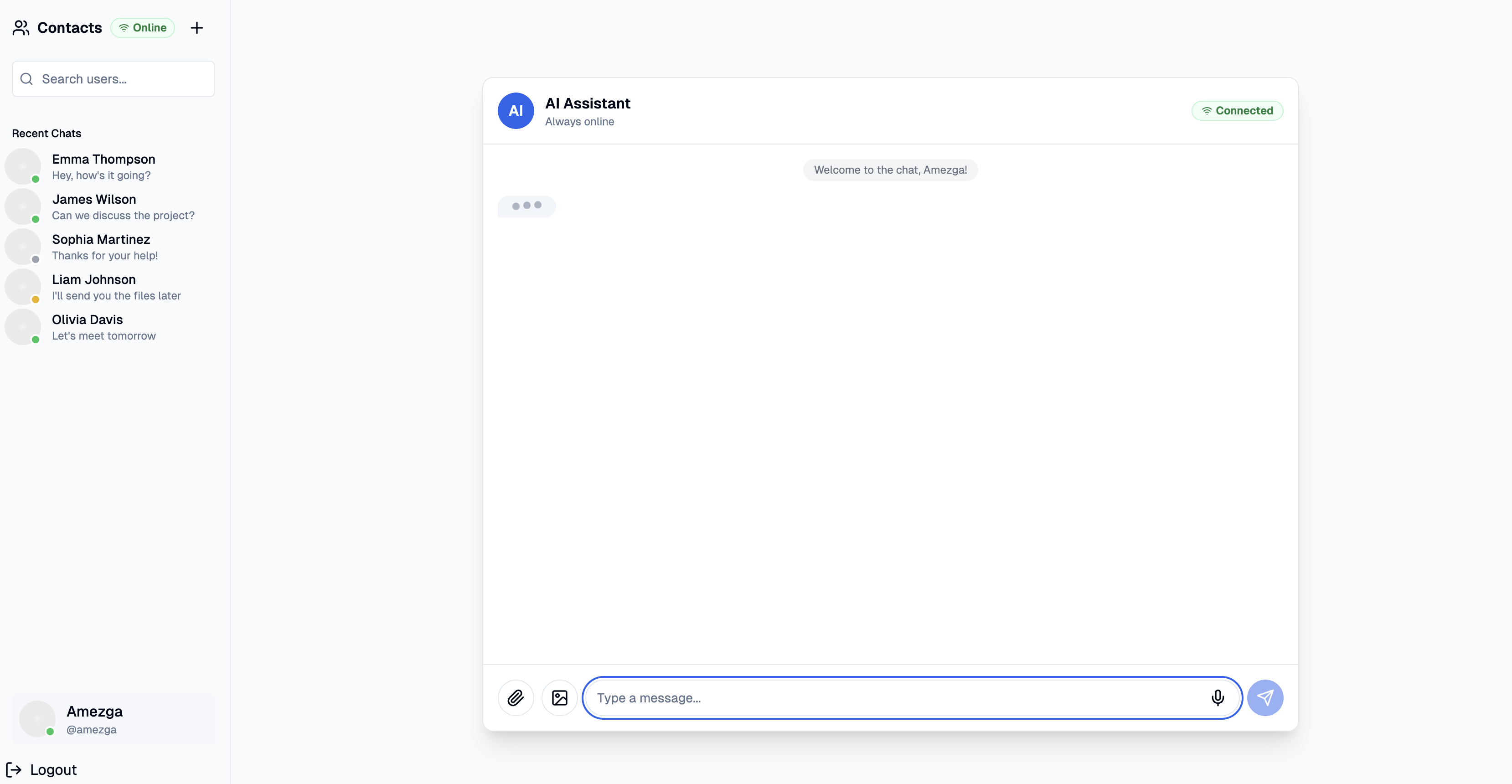
A real-time messenger built with FastAPI and WebSockets, featuring DynamoDB for message storage and JWT-based authentication. It combines a minimalistic frontend for private conversations with a scalable backend architecture that leverages Python’s asyncio for efficient concurrent resource access and asynchronous SQLAlchemy for non-blocking database operations. The app supports persistent chat history, user presence tracking, and session restoration.

Designed and implemented a scalable data lake using S3 and Apache Iceberg, enabling efficient storage and querying of large datasets with proper partitioning and optimization. Integrated it into ingestion and analytics pipelines to support both raw and transformed data workflows, with automated compaction and schema evolution support.
My Bookshelf

Clean Code: A Handbook of Agile Software Craftsmanship
Robert C. Martin
A handbook for writing clean, maintainable code

Clean Architecture: A Craftsman's Guide to Software Structure and Design
Robert C. Martin
A guide to creating software structures that are easy to understand, maintain and extend

Designing Data-Intensive Applications
Martin Kleppmann
The big ideas behind reliable, scalable, and maintainable systems

Head First Design Patterns
Eric Freeman & Elisabeth Robson
A brain-friendly guide to design patterns

Python Concurrency with asyncio
Matthew Fowler
Learn how to write concurrent code in Python

System Design Interview
Alex Xu
An insider's guide to system design interviews

Fundamentals of Software Architecture
Neal Ford & Mark Richards
An engineering approach to software architecture

Fluent Python
Luciano Ramalho
Clear, concise, and effective programming with Python

PostgreSQL Query Optimization
Dombrovsky, Novikov, Beylikova
Techniques for optimizing queries in PostgreSQL databases

…and others
Other great books on system design, architecture, team workflows, and Python internals that shaped my thinking.